1장 분석 모형 설계
- 분석 모형을 선정하고 설계하는 방법에 대해 학습
핵심키워드
- 통계기반분석
- 데이터 마이닝
- 데이터 분할
- 과적합
01. 분석 절차 수립
학습목표
- 기본적인 분석 모형들의 종류와 개념, 분석 모형을 구축하는 방법론에 대해 학습
1. 분석 모형 선정
- 분석 목적에 부합하고 수집된 데이터의 변수들을 고려하여 적합한 빅데이터 분석 모형을 선정
- EDA(Exploratory Data Analysis, 탐색적 자료 분석)
- 시각화와 기술통계를 통해서 데이터를 이해하는 단계
- 독립변수와 종속변수
- 독립변수
- 입력값이나 원인이 되는 변수
- 설명변수, 실험변수, 예측변수, 통제변수, 조작변수 등
- 종속변수
- 결과물이나 효과를 나타내는 것
- 결과변수, 반응변수, 목표변수, 출력변수, 의존변수 등
- 독립변수
통계 기반 분석
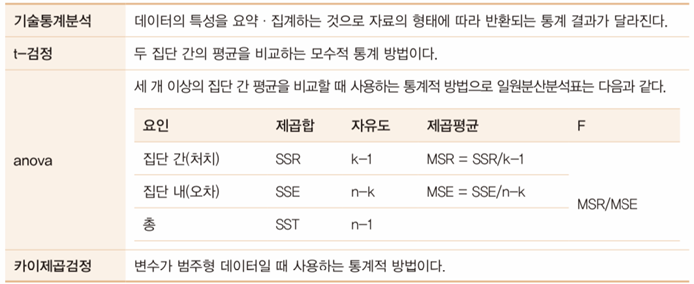
- 기술통계분석
- 자료형태
- 질적 척도
- 명목척도
- 서열척도
- 양적 척도
- 등간척도
- 비율척도
- 질적 척도
- 자료형태
- t-test
- 표본이 독립성, 정규성, 등분산성을 만족할 때 사용할 수 있다.
- 카이제곱검정(Chi square test)
- 독립성 검정
- 변수가 두 개일 때 이 두 변수 사이에 연관성이 있는지 없는지를 검정
- 동질성(동일성) 검정
- 변수가 하나이고 이 변수가 2개 이상의 범주로 구분 될때 그룹간에 차이가 있는지를 검정
- 독립성 검정
- 분산분석(ANOVA)
독립변수는 범주형 데이터
종속변수는 연속형 데이터
F-value 사용 : ‘집단 간 분산 ÷ 집단 내 분산’으로 계산
일원분산분석
- 독립변수와 종속변수 모두 한 개일 때 사용
예) 연령대별 유튜브 시청 시간의 차이
- 독립변수 : 연령대(청소년, 성인, 노인)
- 종속변수 : 시청시간
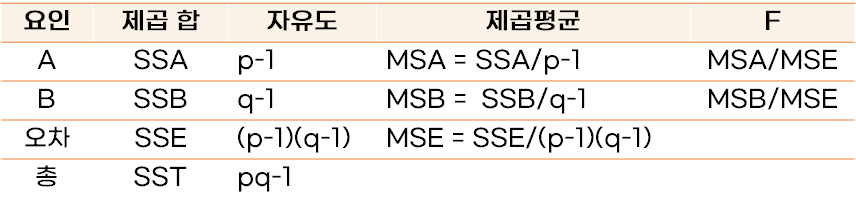
이원분산분석
- 독립변수의 수가 두 개 이상일 때 사용
- 이원분산분석은 데이터에 반복이 없는 경우와 있는 경우로 구분
- 독립변수 간 교호작용이 있다고 판단될 때는 반복이 있는 실험
- 독립변수 간 교호작용이 없다고 판단될 때(두 독립변수가 독립인 경우) 반복이 없는 실험
- 반복이 없는 실험은 주효과 분석
- 반복이 있는 실험은 주효과 분석과 교호작용 분석
- [case] 성별과 연령대별 유튜브 시청 시간의 차이
- 성별의 주효과 : 성별이 시청 시간에 영향을 주는가?
- 연령대의 주효과 : 연령대가 시청 시간에 영향을 주는가?
- 성별과 연령대의 교호작용 : 성별과 연령대가 서로 영향을 주는가?
[반복이 없는 이원분산분석표(p, q는 집단의 수)]
[반복이 있는 이원분산분석표(p, q는 집단의 수, r은 반복 횟수)]
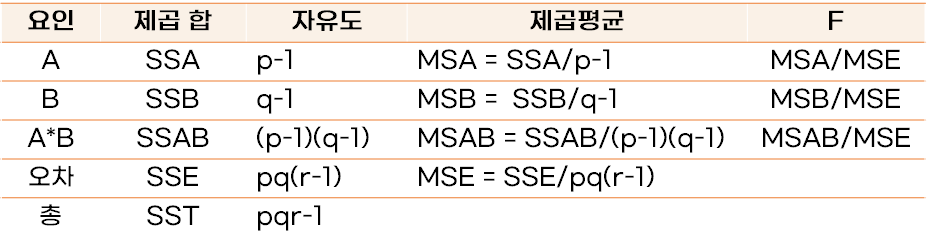
다원변량분산분석
- 종속변수가 2개 이상인 경우 집단 간의 평균 차이를 검증하기 위해 사용하는 분석 방법
데이터 마이닝
- 대규모로 저장된 데이터 속에서 분석을 통해 유의미한 패턴과 규칙을 찾아내는 과정
- 진행순서
- 목적 정의 단계
- 분석의 목적과 필요한 데이터를 정의
- 데이터 준비 단계
- 필요한 데이터를 수집하고 데이 정제 및 데이터 품질 보장
- 데이터 가공 단계
- 분석 목적에 맞게 목표 변수를 정의하고 분석기법 적용이 가능한 형태로 데이터를 가공
- 데이터 마이닝 기법 적용 단계
- 분석기법을 적용해 목적하는 정보를 추출
- 검증 단계
- 추출한 정보를 검증
정형 데이터 마이닝

- 기술
- 사물의 특질을 객관적, 조직적, 논리적으로 적는 것
- 어떤 사실을 차례를 쫓아 말하거나 적는 것
- 분류
- 종속변수가 범주형 혹은 이산형일 때 사용하는 방법
- 입력변수를 근거로 데이터가 어떤 그룹에 속하는지 분류하고, 등급을 나누는데 사용
- 어떤 일이 일어날 가능성이 높은 집단과 낮은 집단의 분류
- 고객의 신용평가(우량, 불량), 고객의 이탈방지(이탈, 유지) 등에 사용
- 추정
- 목표변수가 연속형일 때 사용 가능한 방법
- 예) 부모의 데이터를 기반으로 자녀의 키를 추정
- 예측( 추정 vs. 예측)
- 종속변수가 연속형 데이터일 때 사용 가능한 방법
- 미래의 기업가치 예측, 부동산 가격 예측, 코로나 확진자 수 예측 등에 사용
- 연관분석
- 장바구니 분석
- 교차 판매를 위해 사용
- 영화/VOD 등 디지털 콘텐츠 구매 분석
- 동시에 판매될 가능성이 높은 상품들의 연관성을 발견하여 상품 진열, 패키지 기획 등
- [case] 연관 규칙은 if A Then B 와 같이 조건과 반응의 형태로 구성
- A사건이 발생하면 B사건이 일어난다.
- 치즈케이크를 먹는 손님 중 30%는 아이스 아메리카노를 마신다.
- 군집( 분류 vs. 군집)
- 분류분석과 달리 별도의 종속변수가 요구되지 않음
- 개체간의 유사성에만 기초하여 군집을 형성
- 데이터 그 자체가 지닌 다른 데이터와의 유사성에 의해 그룹화, 세분화
- 마케팅에서 고객을 세분화하는 데 사용
- 고객을 세분화할 때 고객의 성별, 연령, 니즈, 특성, 구매 동기, 가치, 행동 패턴 등에 따라 그룹화
- 고객 세분화를 바탕으로 마케팅 전략 수립
비정형 데이터 마이닝

분석 모형 유형

모형 선정 프로세스
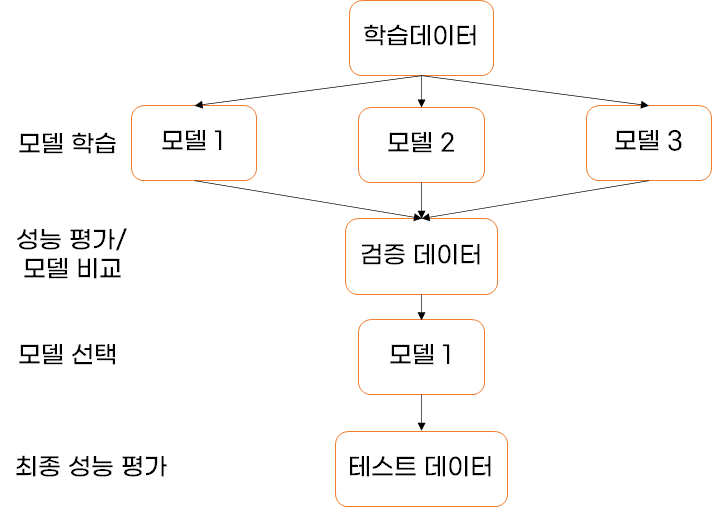
- 그리드 서치(Grid Search)를 이용한 모델 선택
- 관심 있는 하이퍼파라미터를 대상으로 가능한 모든 조합을 시도하여 최적의 파라미터 값을 찾는 방법
- 하이퍼파라미터를 적용해 모델을 학습할 때마다 성능을 평가하고 최종적으로 가장 좋은 성능이 나온 모델을 선정
- 장점
- 주어진 후보 내에서 가장 좋은 결과를 얻을 수 있다
- 단점
- 모든 경우의 수를 시도하기 때문에 하이퍼파라미터의 수가 증가할수록 전체 탐색 시간이 기하급수적으로 증가
- 랜덤 서치(Random Search)를 이용한 모델 선택
- 그리드 서치의 단점을 보완하기 위해 나온 방법
- 작동 원리는 그리드 서치와 거의 동일
- 하이퍼파라미터 값의 범위를 지정하고 지정한 범위 내에서 랜덤 샘플링을 통해 하이퍼파라미터 조합을 생성
2. 분석 모형 정의
지도학습과 비지도학습
- 객체의 특성을 머신러닝 분석 모델에 학습시키는 과정
- 지도학습
- 정답이 있는 데이터를 활용해 분석 모델을 학습시키는 것
- 비지도학습
- 정답을 알려주지 않고 학습하는 것
분석 모형 종류
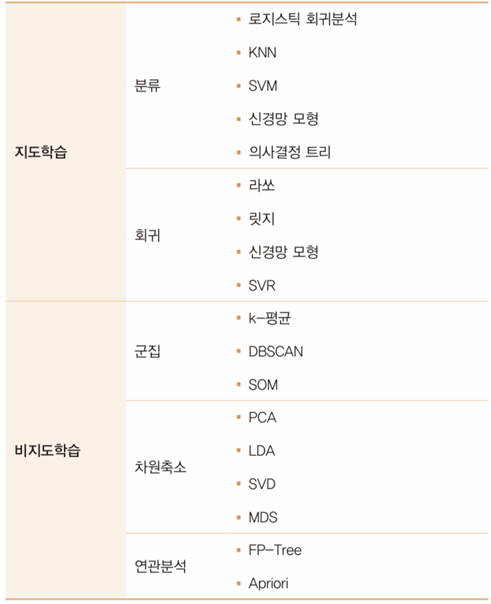
상황에 따른 모형 선정
3. 분석 모형 구축 절차
분석 모형 구축 절차
폭포수 모델- 과정을 순차적으로 진행하는 방법, 하향식 방법론
- 폭포수 모델 프로세스

- 요구사항 분석
- 사용자의 요구사항을 수집
- 기능, 제약 조건, 목표 등을 설정
- 사용자가 요구하는 태스크를 이해하는 단계
- 요구사항 명세서를 작성
- 설계
- 요구사항 명세서를 참고해 그것을 준수하는 설계 작업을 실행
- 문제를 해결하는 방안에 집중하는 단계
- 기본 / 상세 설계서를 작성
- 구현
- 설계 단계에서 작성된 설계서를 기반으로 프로그램을 작성
- 단위 테스트 및 코드 검증을 수행
- 이 단계에서의 산출물은 프로그램 소스 코드
- 테스트
- 완성된 코드를 정식으로 테스트하는 단계
- 프로그램의 오류를 발견하고 수정
- 테스트 결과 보고서를 작성
- 유지보수
- 시스템을 사용하면서 발생하는 오류를 수정
- 새로운 기능을 추가
- 폭포수 모델의 장단점

프로토타이핑 모델- 폭포수 모델의 단점인 피드백에 의한 반복이 어렵다는 점을 극복하기 위해 만든 점진적 프로세스 모델
- 프로토타이핑 모델 플로차트
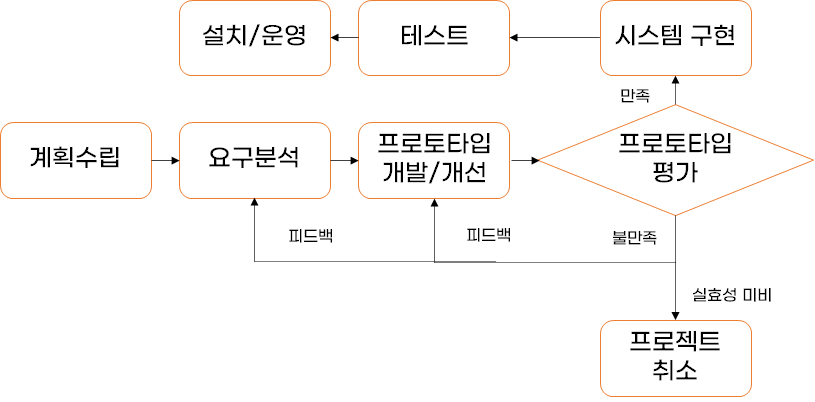
- 계획 수립
- 개발의 타당성을 검증
- 프로젝트 진행 여부를 결정
- 개발 계획을 수립
- 요구분석
- 사용자의 요구사항을 수집하고 그것을 명세화
- 프로토타입에 포함할 주요 요구사항을 정의
- 프로토타입 개발/개선
- 요구분석에서 정의한 주요 요구사항을 기반으로 프로토타입 모델을 개발
- 평가 단계에서 추가 및 수정되는 요구사항을 반영
- 프로토타입 평가
- 개발된 프로토타입 모델에 사용자의 요구사항이 잘 반영되었는지 평가
- 프로토타입을 검토해 프로젝트 진행 및 최소 여부를 결정
- 추가 요구사항 및 개선사항이 있을 시 전 단계로 돌아가 개선작업
- 시스템 구현
- 프로토타입의 기능을 확장하여 실제 시스템으로 구현
- 단위테스트 및 코드 검증을 실행
- 테스트
- 완성된 코드를 정식으로 테스트하는 단계
- 프로그램의 오류를 발견하고 수정
- 통합 테스트, 시스템 테스트, 인수 테스트 등을 수행
- 프로토타이핑 모델의 장단점

나선형 모델- 시스템을 개발하면서 발생하는 위험을 최소화하기 위해 개발 단계를 반복적으로 수행하며 점진적으로 완벽한 시스템을 개발하는 모델
- 폭포수 모델의 장점과 프로토타입 모델의 장점을 합침
- 위험 분석이라는 새로운 요소를 추가해 만든 모델
- 나선형 모델의 개발 단계
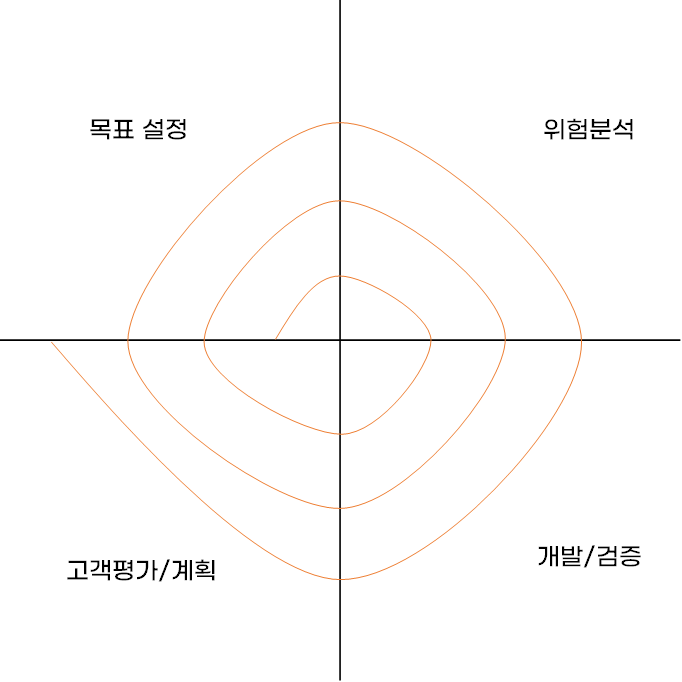
- 목표 설정
- 요구사항을 분석
- 프로젝트 계획을 수립
- 한 사이클이 끝난 후 고객의 평가를 반영
- 목표는 사이클이 반복될 때마다 변경될 수 있음
- 위험 분석
- 요구사항을 토대로 위험요소를 정의
- 이미 존재하는 위험요소의 원인을 파악하고 발생 가능한 위험을 예측
- 위험요소에 대한 대안을 수립하고 위험을 최소화
- 개발/검증
- 개발 모델을 선택
- 위험요소를 기반으로 모델을 개발
- 모델을 점진적으로 발전시켜 최종모델을 개발
- 고객평가/계획
- 사용자와 의사소통하는 단계
- 구축된 모델을 사용자가 평가
- 추가 및 수정할 사항이 있다면 그것을 반영하기 위한 차후 계획을 수립
- 추가 반복 여부를 결정
- 나선형 모델의 장단점

02. 분석 환경 구축
학습목표
- 분석에 사용하는 여러가지 도구와 분석을 위해 데이터를 분할하는 방법에 대해 학습
1. 분석 도구 선정
분석 도구 선정
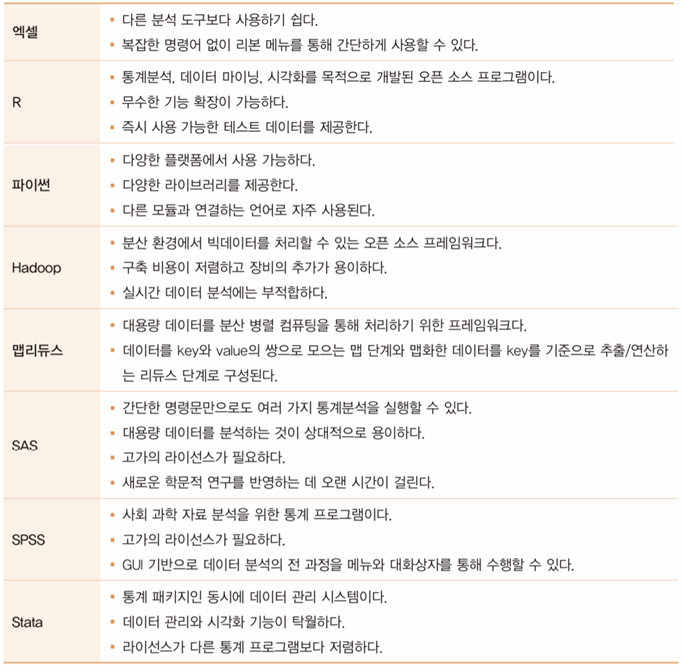
2. 데이터 분할
데이터셋 분할

데이터 분할 시 주의사항
- 대표성
- 각 데이터셋은 전체 데이터에 대한 대표성을 띠고 있어야 한다
- 시드 설정(seed)
- 시드(seed)를 설정하지 않을 경우 데이터를 분할할 때 마다 학습용, 검증용, 테스트 데이터셋에 각각 다른 데이터가 들어간다.
- 그렇게 되면 정확한 성능을 평가하기가 어렵기 때문에 데이터를 분할할 때는 시드를 설정해야 한다.
- 시간의 흐름
- 시계열 분석을 위한 데이터의 경우 데이터를 분할할 때
- 학습용 데이터에는 가장 과거의 데이터
- 검증용 데이터에는 그다음 오래된 데이터
- 테스트 데이터에는 가장 최신의 데이터가 들어가게 분할해야 한다.
- 시계열 분석을 위한 데이터의 경우 데이터를 분할할 때
- 중복
- 데이터를 분할할 때 학습용, 검증용, 테스트용 데이터셋에는 중복이 있으면 안 된다.
- 각 데이터셋에 데이터가 중복된 데이터로 인해 정확한 성능 평가가 어렵다.
과적합과 과소적합
- 과적합
- 모델이 학습 데이터를 과하게 학습하는 것
- 과소적합
- 모델이 너무 단순해서 학습 데이터조차 제대로 예측하지 못하는 경우

데이터 분할 방법

출처
- 내용 출처
이지패스 2021 빅데이터분석기사 필기(수험서 앱 제공) / 위키북스 / 전용문, 정다혜, 임예은, 오경서 지음
[빅데이터 분석기사 필기 | 3. 빅데이터 모델링 (1) 분석 모형 설계] - 세우초밥