1장 데이터 전처리
데이터 분석에 앞서 데이터 전처리는 반드시 거쳐야 하는 과정.
핵심 키워드
- 데이터 정제
- 분석변수 처리
- 차원의 축소
- 클래스 불균형
01 데이터 정제
1. 데이터 전처리의 이해
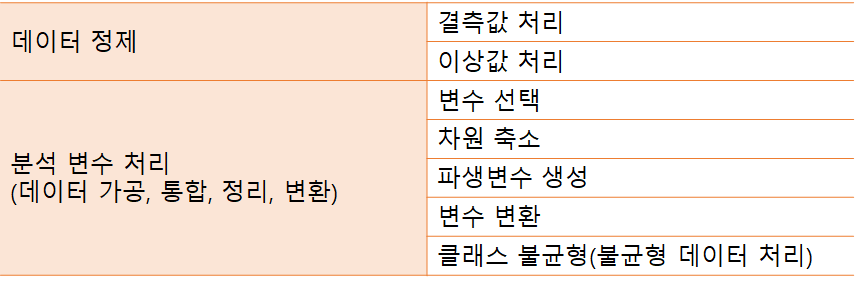
데이터 전처리
- 데이터 분석을 위한 필수 과정으로 데이터를 정제한 뒤, 데이터 가고으 통합, 정리, 변환을 통해 데이터 분석 변수를 처리하는 등의 작업으로 데이터 분석 결과의 신뢰도를 높이기 위한 과정
데이터 전처리의 중요성
- 전처리 결과가 분석 결과에 직접적인 영향을 주기 때문에 전처리는 반복적으로 수행해야 함
- 데이터 분석의 단계 중 가장 많은 시간이 소요되는 단계가 데이터 수집과 데이터 전처리 단계임
- 데이터 정제 → 결측값 처리 → 이상값 처리 → 분석 변수 처리
2. 데이터 정제
데이터 정제

데이터 결측값
- 결측값
- 필수적인 데이터가 입력되지 않고 누락된 값
- 처리 방법 :
- 중심 경향값 넣기 (평균값, 중앙값, 최빈값)
- 분포 기반 처리

데이터 이상값
- 이상값
- 데이터의 범위에서 많이 벗어난 아주 작은 값이나 아주 큰 값
- 처리 방법 :
- 하한보다 낮으면 하한값 대체
- 상한보다 높으면 상한값 대체

노이즈
- 노이즈
- 실제는 입력되지 않았지만 입력되었다고 잘못 판단한 값
- 처리 방법 :
- 일정 간격으로 이동하면서 주변보다 높거나 낲으면 평균값 대체
- 일정 범위 중간값 대체
특정값 대체법의 종류
- 평균 대체법 : 평균, 중앙값, 최빈값 등의 대푯값으로 대체하는 방법
- 단순 확률 대체법 : 평균값으로 대체 시 발생할 수 있는 추정량 표준 오차의 과소 추정 문제를 보완하기 위한 방법
- 보삽법 : 시계열 자료의 누락된 데이터를 보완하기 위해 사용. 매해 자료를 수집하는 경우, 한 해의 데이터가 결측인 경우 나머지 관측치만을 가지고 평균을 계산하는 방법
- 평가치 추정법 : 약간의 오차는 감수하면서 원래의 값을 추정하는 방법
- 다중 대치법 : 결측 데이터가 있는 데이터셋을 결측치 추정을 통해 완벽한 데이터셋으로 생성한 뒤, 결측치가 채워진 데이터셋을 통해 결측치를 추정. 여러 번의 결측치 추정은 오류를 줄이는 데 도움이 되며 기존 데이터의 불확실성을 유지하면서 결과를 얻을 수 있다.
- 완전정보 최대우도법 : 적합함수인 최대우도를 바탕으로 결측치가 없느 케이스로부터 추정되는 모형모수를 가지고 가중평균을 구성하여 결측치 대신 사용하는 방법
02 분석 변수 처리
1. 변수 선택
변수 선택

변수 선택법
- 부분 집합법(All subset)
- 모든 가능한 모델을 고려하여 가장 좋은 모델을 선정하는 방법
- 변수가 많아짐에 따라 검증해야 하는 회귀 분석도 만아지는 단점
- 변수의 개수가 적은 경우 높은 설명력을 가진 결과를 도출해내는데 효과적
- ‘임베디드 기법’ 이라고도 하며 라쏘, 릿지, 엘라스틱넷 등의 방법을 사용
- 단계적 변수 선택방법
- 전진 선택법
- 변수의 개수가 많을 때 사용할 수 있지만, 변숫값이 조금만 변해도 결과에 큰영향을 미치기 때문에 안정성이 부족한 방법.
- 상관계수의 절댓값이 가장 큰 변수에 대해 부분 F 검정으로 유의성 검정을 하고 더는 유의하지 않은 경우 해당 변수부터는 더 이상 변수를 추가하지 않는다.
- 후진 제거법
- 다중공선성이 높게 나타난 변수를 하나씩 제거하는 후진제거법을 적용하는 것
- 다중공선성
- 일부 설명 변수가 다른 설명변수와 상관정도가 높아 데이터 분석 시 부정적인 영향을 미치는 것을 의미
- 다중공선성
- 전체 변수의 정보를 이용한다는 장점
- 변수의 개수가 너무 많은 경우 적용하기 어렵다
- 다중공선성이 높게 나타난 변수를 하나씩 제거하는 후진제거법을 적용하는 것
- 단계적 방법
- 전진 선택법과 후진 제거법을 보완한 방법
- 변수를 연속적으로 추가 혹은 제거하면서 AIC가 낮아지는 모델을 찾는 방법
- 전진 선택법
단계적 변수 선택 방법

AIC(Akaike’s Information Criterion)
- AIC 값이 작을수록 상대적으로 좋은 모델이라고 판단할 수 있다
- AIC = -2ln(L) + 2K
- -2ln(L) = 모형의 적합도
- L = 우도값
- K = 상수항을 포함한 모든 독립변수의 수
- AIC는 주어진 데이터에 대한 통계 모델의 상대적인 품질을 평가하는 기준
- AIC를 최소화한다는 것은 우도를 가장 크게 하는 동시에 변수의 수는 가장 적은 최적의 모델을 의미
2. 차원 축소
차원축소

LDA는 투영을 통해 가능한 클래스를 멀리 떨어지게 하므로 SVM 같은 다른 분류 알고리즘을 적용하기 전에 차원을 축소하는데 자주 사용된다.
LDA는 데이터를 최적으로 분류하여 차원을 축소, PCA는 데이터를 최적으로 표현하는 관점에서 데이터를 축소하는 방법
LDA를 적용할 때 베이지안 정리(Bayes’ Theorem)를 활용
베이지안 정리(선형판별분석에서는 판별함수라고 칭함)
- 사전확률 (P(A))로부터 사후 확률(P(A|B))을 구하는 것
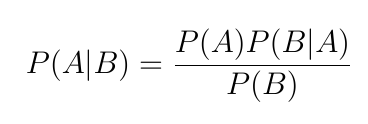
친밀도 : t-SNE 과정에서 측정한 거리를 기준으로 t-분포의 값
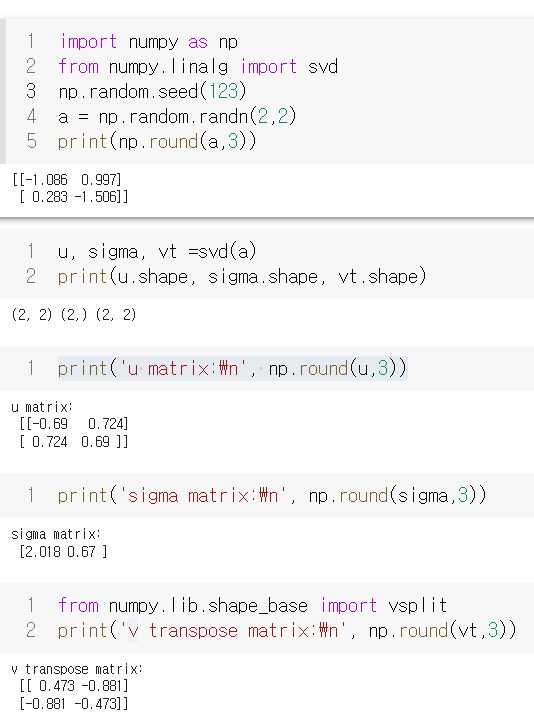
SVD
일반적으로 정방행렬에 대해서는 고윳값 분해를 적용
직사각 행렬에 대해서는 고윳값 분해를 이용할 수 없음
데이터 압축 등의 많은 분야에서 활용
U = M * M^T를 고윳값 분해해서 얻은 직교행렬
V = M^T * M을 고윳값 분해해서 얻은 직교행렬
- 행렬 U와 V에 속한 벡터는 특이벡터(Singular Vector)
- 서로 직교하는 성질
∑ = 대각행렬
- 대각성분은 M * M^T과 M^T * M의 고윳값에 루트를 씌운 값으로 구성
- 대각에 위치한 값만 존재하고 나머지 위치의 값은 모두 0인 행렬
- ∑ 행렬에서 0이 아닌 값들이 바로 특잇값
특잇값의 개수는 행렬의 열과 행의 개수 중 작은 값과 같다.
고윳값과 고유벡터
- 정방 행렬 A에 대해 다음 식을 만족하는 영벡터가 아닌 벡터 v, 실수 λ를 찾을 수 있다고 가정하자.
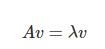
- 위 식을 만족하는 실수 λ를 고윳값(eigenvalue), 벡터 v를 고유벡터(eigenvector)라고 한다. 고윳갑과 고유벡터를 찾는 작업을 고유분해(eigen-decomposition) 또는 고윳값 분해(eigenvalue decomposition)라고 한다.
- 행렬 A의 고유벡터는 행렬 A를 곱해서 변환을 해도 방향이 바뀌지 않는 벡터
Python을 통한 SVD 예시
3. 파생변수 생성
파생변수
- 기존 변수들을 조합하여 새롭게 만들어진 변수를 파생변수라 한다.
- 분석가의 주관이 포함
- 논리적 타당성을 충분히 고려해 생성
파생변수 생성 방법
- 하나의 변수에서 정보를 추출해 새로운 변수를 생성
- 주민등록번호에서 나이와 성별을 추출
- 한 레코드의 값을 결합하여 파생변수를 생성
- 키와 몸무게를 이용해 BMI 지수라는 변수를 생성
- 조건문을 이용해 파생변수를 생성
- 기준값을 정하고 조건문을 통해 BMI 지수에 따라 저체중, 정상 체중, 과체중을 구분한 파생변수를 생성
- R로 파생변수 만들기
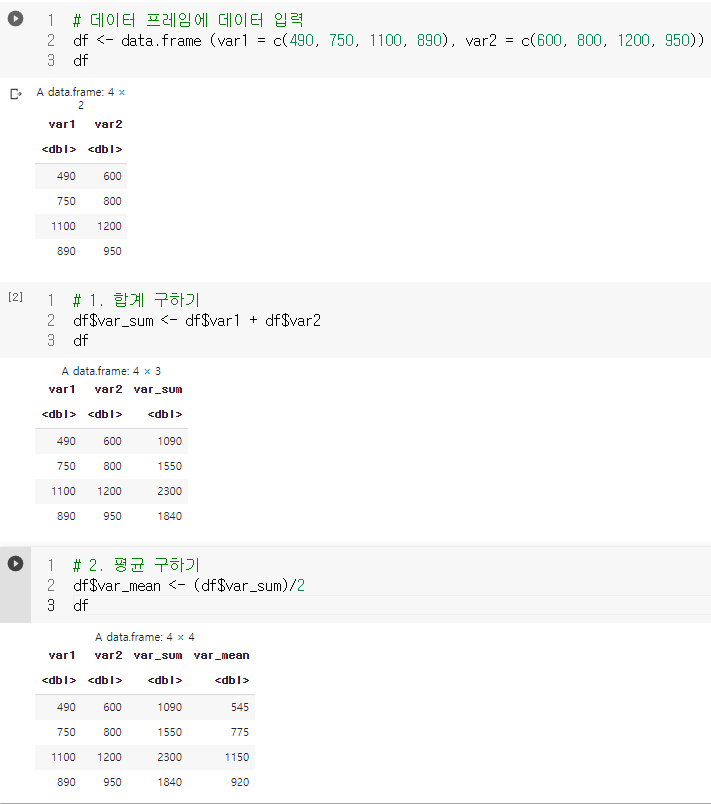
4. 변수 변환
변수 변환

5. 클래스 불균형(불균형 데이터 처리)
- 어떤 데이터에서 각 클래스가 가지고 있는 데이터의 양에 큰 차이가 있는 경우
- 불균형 데이터를 사용하여 모델링을 할 경우 관측치 수가 많은 데이터를 중심으로 학습이 진행되기 때문에 관측치가 적은 데이터에 대한 학습은 제대로 이루어지지 않을 가능성이 크다.
클래스 불균형 문제 해결 방법
- 과소표집(Under Sampling)
- 무작위로 정상 데이터를 일부만 선택해 유의한 데이터만 남기는 방법
- 정상 데이터 800개, 페이크 데이터 100개 → 정상 데이터를 제거해 100개로 감소
- 과대표집(Over Sampling)
- 사전에 정해진 기준 또는 기준 없이 무작위로 소수 데이터를 복제하는 방법
- 정상 데이터 500개, 페이크 데이터 20개 → 페이크 데이터를 복제하여 500개로 증가
- SMOTE(Synthetic Minority Oversampling Technique)
- 다수 클래스를 샘플링하고 기존의 소수 샘플을 보간하여 새로운 소수 인스턴스를 합성해내는 방법.
- 알고리즘을 통해 소수 클래스에 새로운 데이터를 생성
- 소수 클래스의 데이터 하나를 찾고 해당 데이터와 가까운 K개의 데이터를 찾은 후 주변 값을 기준으로 새로운 데이터를 생성
- 소수 클래스 수는 다수 클래스의 수와 동일해지게 된다.
- 다수 클래스를 샘플링하고 기존의 소수 샘플을 보간하여 새로운 소수 인스턴스를 합성해내는 방법.
클래스 불균형

출처
- 내용 출처
이지패스 2021 빅데이터분석기사 필기(수험서 앱 제공) / 위키북스 / 전용문, 정다혜, 임예은, 오경서 지음
[빅데이터 분석기사 필기 | 2. 빅데이터 분석 기획 (1) 데이터 전처리]- 세우초밥
베이지안 정리
고유값 분해
https://datascienceschool.net/02 mathematics/03.03 고윳값 분해.html