3장. 데이터 수집 및 저장 계획
이 장은 데이터를 분석하기 전 단계의 과정을 다루고 있다.
핵심키워드- 데이터의 유형
- 데이터의 변환
- 데이터 저장과 처리
- 하둡 에코시스템
01_ 데이터 수집
학습목표
- 데이터를 수집하고 분석에 활용할 수 있도록 변환하는 과정을 학습한다
- 데이터의 품질을 검증하는 방법을 학습한다.
1. 데이터 수집의 이해와 수집 방법
데이터 수집에서 고려할 사항
- 데이터의 위치
- 데이터의 주기
- 데이터의 수집 방법
- 데이터의 저장 형태
데이터를 수집하는 절차
- 데이터 선정 : 데이터 선정은 데이터 분석 결과와 품질에 큰영향을 미친다. 데이터 선정 시 우선 고려할 사항은 수집 가능성이다.
- 수집 세부 계획 수립 : 데이터 위치와 유형을 파악하고 그에 맞는 준비를 해야 한다. 데이터의 위치가 시스템 내부 혹은 외부에 있는지를 파악하고 그에 맞는 기술 및 보안 정책 등을 파악해야 한다.
- 테스트 수집 실행 : 수집 가능성, 보안 문제, 정확성 등을 만족하는지 검증하고 실제 활용 가능성까지 검토해야 한다.
데이터 유형에 따른 데이터 수집 방법
| 데이터 유형 | 데이터 종류 | 데이터 수집 방법 |
|---|---|---|
| 정형 데이터 | DBMS, 스프레드시트 | ETL, FTP, Open API |
| 반정형 데이터 | HTML, XML. JSON, 웹 문서, 웹 로그, 센서 데이터 | 웹 크롤링, RSS, Open API, FTP |
| 비정형 데이터 | 소셜 데이터, 문서, 이미지, 오디오, 비디오, IoT | 웹 크롤링, RSS, Open API, Streaming, FTP |
2. 데이터 유형 및 속성 파악
정형 데이터와 비정형 데이터
| 정형 데이터(Structured Data) | - 고정된 구조로 정해진 필드에 저장된 데이터 - 엑셀 스프레드시트, RDBMS(관계형 데이터베이스), CSV 파일 형태 - 데이터로서 활용성이 가장 높다. |
|---|---|
| 반정형 데이터(Semi-Structured Data) | - 고정된 필드에 저장되어 있지는 않지만, 데이터와 메타데이터, 스키마 등을 포함하는 데이터 - XML,HTML,JSON - 규칙을 가지고 있어 필요 시 정형 데이터로 변형이 가능하다. |
| 비정형 데이터(Unstructured Data) | - 미리 정해진 구조가 없고, 고정된 필드에 저장되어 있지 않은 데이터 - 동영상, 소셜 네트워크 댓글 같은 문자 데이터, 위치 데이터, 오디오 데이터 등 - 비정형 데이터는 크기가 크고 규칙이 없어 복잡하다 - 데이터 변환 기술의 발전으로 비정형 데이터의 활용성과 공유 가능성이 높아지고 있다. |
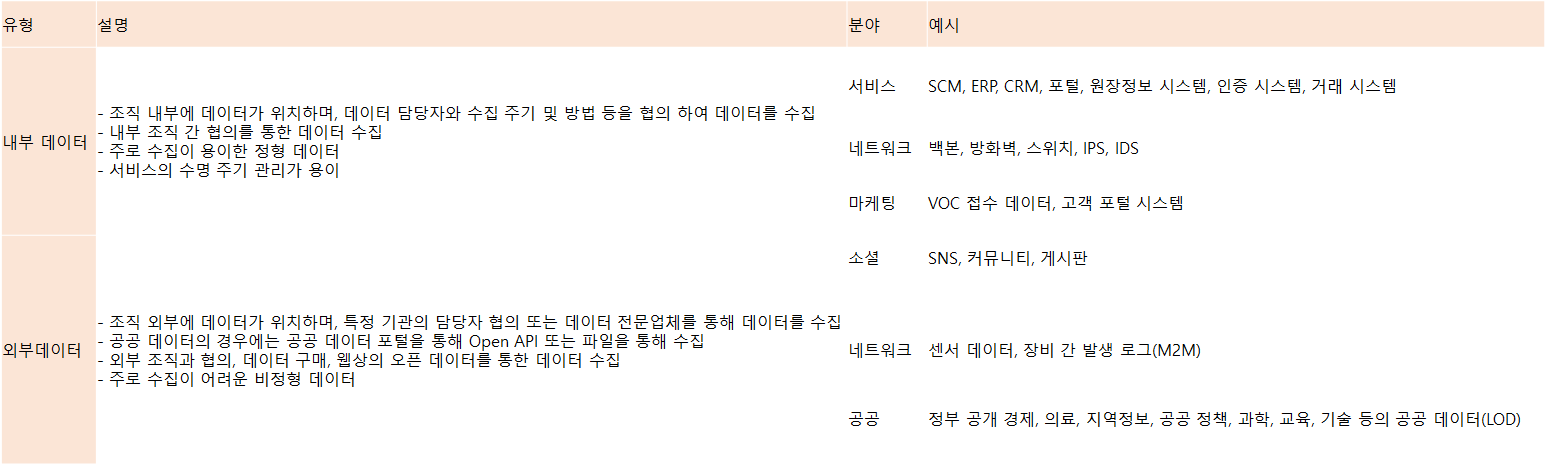
내부 데이터와 외부 데이터
3. 데이터 변환
데이터 변환 방법
평활화(Smoothing)- 데이터로부터 발생할 수 있는 잡음을 제거하기 위해 추세에 맞니 않는 이상값들을 제거하여 데이터를 변환하는 방법
집계(Aggrengation)- 그룹화 연산을 데이터에 적용하여 데이터를 요약하는 방법
- 일반적으로 다중 추상 레벨에서 데이터 분석을 위한 데이터 큐브 생성에 사용
- 예를 들면 매일 발생하는 데이터를 월별 또는 연도별로 그룹화하는 총계를 계산해 요약하는 조치를 취함
일반화(Generalization)- 특정 구간에 분포하는 값으로 스케일(규모)을 변화시키는 방법
- 데이터를 특정 범위 내의 값으로 축소하는 것을 의미
- 예측 모델이 새로운 자료에 얼마나 잘 적용되는가를 의미
- 최솟값과 최댓값의 편차가 크거나 다른 열보다 데이터가 지나치게 큰 열이 있을 때 주로 사용
- 일반화는 데이터 마이닝 기법의 비정형성을 어느 정도 해결하고 보완하는 데 도움
정규화(Normalization)- 데이터를 특정 구간 안에 들어가게 이상값을 변환하는 방법
- 최단 근접 분류와 군집화 같은 거리 측정 등에 특히 유용
- 구체적인 방법으로는 최소-최대 정규화, z-score 정규화, 소수 스케일링 정규화
- 정규화의 종류
- 최소-최대 정규화 : 원본 데이터에 대해 선형 변환을 수행함으로써 정규화하는 방법으로, 원본 데이터 값들의 관계를 그대로 유지하는 방법
- z-score 정규화 : 평균값과 표준편차를 기초로 하여 정규화하는 방법으로, 실제로 최솟값과 최댓값이 알려져 있지 않거나 최소-최대 정규화에 큰 영향을 주는 이상치가 있는 경우에 이용할 수 있는 방법
- 소수점 변경 정규화 : 소수점을 변경하여 정규화하는 방법으로, 정규화된 값의 절댓값은 1보다 작아야 한다.
범주화- 데이터 통합을 위해 상위 레벨 개념의 속성이나 특성을 이용해 일반화하는 방법
- 상위 개념으로 통합하는 것을 의미(나이 : 30대, 40대/ 까치, 까마귀 : 새, 동물)
- 이산화 : 연속형 변수를 이산 변수로 변환하는 방법
- 이산화 방법은 인접 구간의 처리 방법에 따라 분할 이산화, 병합 이산화로 나누거나 클래스 정보 활용 여부에 따라 지도 이산화, 비지도 이산화로 나눌 수 있다.
- 이진화 : 연속형과 이산형 속성을 한 개 이상의 이진 속성으로 변환하는 것
- 이산화 : 연속형 변수를 이산 변수로 변환하는 방법
데이터 축소 · 차원 축소
| 데이터 축소 | 같은 정보량을 가지면서 데이터의 크기를 줄이는 방법이다. 대규모 데이터를 다루는 경우 데이터 분석의 효율성을 높이기 위해 필요한 데이터 변환 과정이다. |
|---|---|
| 차원 축소 | 차원 축소를 통해 데이터 잡음을 제거할 수 있으며 데이터셋을 더 다루기 쉽게 만들어 준다는 장점이 있다. 여러 속성 중 분석하는 데 관계없거나 중복되는 속성을 제거하는 작업을 통해 속성의 최소 집합을 찾아내는 방법이다. |
| 데이터 압축 | 데이터 인코딩이나 변환을 통해 데이터를 축소하는 방법이다. 아무런 손실 없는 압축기법을 무손실압축기법(Lossless)이라고 하며, 대표적인 예로는 BMP 포맷이 있다. 데이터의 손실이 있는 경우에는 이를 손실압축기법(Lossy)이라고 하고, 대표적인 예로는 JPEG 포맷이 있다. |
4. 데이터 품질 검증
데이터 품질 검증 요소
데이터 품질 검증 요소에는 데이터 값 검증, 데이터 구조 검증, 데이터 관리 프로세스 검증
데이터값 검증- 정형 데이터
정형 데이터의 데이터 값 검증은 대상이 되는 데이터베이스 테이블, 칼럼, 관계, 업무 규칙을 기준으로 데이터 값을 관리하고 분석. 또 데이터 값 품질 기준에 따라 오류를 검출하고 개선안을 제공.
- 비정형 데이터
비정형 데이터의 데이터 값 검증은 비정형 콘텐츠 자체의 상태와 메타데이터에 대한 품질 검증으로 구분.
- 비정형 콘텐츠의 유형에 따라 시각, 청각, 자동화된 도구를 이용해 분석하기 때문에 각각의 품질 기준이 상이
- 메타데이터에 대한 품질 검증은 정형 데이터 품질 검증 방법으로 검증하고 나아가 데이터가 그 콘텐츠를 정확히 식별할 수 있는지, 즉 데이터와 콘텐츠 개체 간의 일치하는 정도까지 무결성의 개념이 확장된다.
데이터 구조 검증- 데이터 구조 검증은 데이터 모델링 관점에서 이루어진다.
데이터 관리 프로세스 검증- 데이터를 관리하는 절차, 인력, 조직을 분석해 문제점을 발견하고 개선할 수 있는 핵심 업무 프로세스를 표준화해 재설계한다.
02_ 데이터의 저장과 처리
학습목표
- 데이터의 저장과 처리 방법, 그리고 빅데이터 플랫폼에 대해 자세히 학습한다.
- 여기서는 가장 널리 활용되는 하둡 플랫폼을 학습하기로 한다.
1. 데이터 저장과 처리
2. 데이터 저장과 처리를 위한 플랫폼
스타 스키마 장단점
| 장점 | 복잡도가 낮아서 이해하기 쉽다. 쿼리 작성이 용이하고 조인의 테이블 수가 적다. |
|---|---|
| 단점 | 차원 테이블들의 비정규화로 데이터 중복이 발생하여 상대적으로 데이터 적재에 시간이 많이 소요된다. |
스노우플레이크 스키마 장단점
| 장점 | 데이터 중복이 제거되어 데이터 적재 시 상대적으로 데이터 적재 소요 시간이 빠르다. |
|---|---|
| 단점 | 복잡성이 증가해 조인 테이블의 개수가 증가한다. 쿼리 작성의 난도가 증가한다. |
ETL 프로세스
데이터 원천으로부터 데이터를 추출 및 변환하여 운뎡 데이터 스토어(ODS : Operational Data Store), 데이터 웨어하우스(Data Warehouse), 데이터 마트(Data Mart)에 데이터를 적재하는 작업
| STEP 1 | Interface | 다양한 이기종 DBMS 및 스프레드시트 등 데이터 원천으로부터 데이터를 획득하기 위한 인터페이스 메커니즘 구현 |
|---|---|---|
| STEP 2 | Staging ETL | 수립된 일정에 따라 데이터 원천(Source)으로부터 트랜잭션 데이터 획득 작업 수행 후, 획득된 데이터를 스테이징 테이블에 저장 |
| STEP 3 | Profiling ETL | 스테이징 테이블에서 데이터 특성을 식별하고 품질을 측정 |
| STEP 4 | Cleansing ETL | 다양한 규칙을 활용해 프로파일링된 데이터 보정 작업 |
| STEP 5 | Integration ETL | 이름, 값, 구조 등 데이터 충돌을 해소하고 클렌징된 데이터를 통합 |
| STEP 6 | Denormalization ETL | 운영 보고서 생성, 데이터 웨어하우스 또는 데이터 마트 데이터 적재를 위해 데이터 비정규화 수행 |
ETL과 CDC의 차이
| ETL | CDC | |
|---|---|---|
| 공통목적 | 원천 데이터를 DW, DM 등에 적재 | 원천 데이터를 DW, DM 등에 적재 |
| 특징 | 실시간이 아닌 정해진 시점의 완료된 데이터를 적재 | 실시간(Real Time) 혹은 준실시간(Near Real Time)으로 적재 |
| 용도 예 | 거래 집계, 일일 회계 집계, 원장 등 이벤트 단위가 아닌 소스 데이터 취합 용도 |
이상 감지 경보, 금융 거래 이상 경보 변경된 이벤트 감지 용도 |
| 기술 | 변경 데이터만 적재 혹은 All Copy (원천 테이블 사용) |
변경 이력을 관리하는 DB Archive Log (원천 테이블이 아닌 Archive Log 시스템 테이블 사용) |
| 적재 수준 | 적재 시점의 적재 수준 (시, 일, 월 등) |
시점에 관계없이 모든 원천 데이터의 변경 로그 기록을 적재 |
ODS 프로세스
ODS는 데이터에 추가 작업을 하기 위해 다양한 원천 데이터로부터 데이터를 추출 통합한 데이터베이스
| STEP 1 | Interface | - 다양한 데이터 원천으로부터 데이터를 획득하는 단계다. - 데이터 원천은 관계형 데이터베이스, 스프레드시트, 플랫 파일, 웹 서비스, 웹 사이트, XML 문서 또는 트랜잭션 데이터를 저장하고 있는 모든 알려진 데이터 저장소(Repository) 등이다. 프로토콜 : - OLEDB(Object Lonking and Embedding Database) - ODBC(Object Data Base Connectivity) |
|---|---|---|
| STEP 2 | Data Staging | - 이단계에서는 작업 일정이 통제되는 프로세스에 의해 데이터 원천으로부터 트랜잭션 데이터가 추출되어 하나 또는 그 이상의 스테이징 테이블에 저장된다. - 이 테이블들은 정규화가 배제되며, 테이블 스키마는 데이터 원천의 구조에 의존적이다. 데이터 원천과 스테이징 테이블과 데이터 매핑은 일대일 또는 일대다로 구성 될 수 있다. |
| STEP 3 | Data Profiling | - 이단계에서는 범위 도메인 유일성 확보 등의 규칙을 기준으로 다음과 같은 절차에 따라 데이터 품질 점검을 한다. - 선행 자료 또는 조건: 데이터 프로파일링 요건 - Step 1 : 데이터 프로파일링 수행 - Step 2 : 데이터 프로파일링 결과 통계 처리 - Step 3 : 데이터 품질 보고서 생성 및 공유 |
| STEP 4 | Data Cleansing | - 이 단계에서는 클렌징 ETL 프로세스로 앞 데이터 프로파일링 단계에서 식별된 오류 데이터를 다음 절차에 따라 수정한다. - 선행 자료 또는 조건 : 데이터 품질 보고서, 데이터 클렌징 요건 - Step 1 : 클렌징 스토어드 프로시저 실행(예비 작업) - Step 2 : 클렌징 ETL 도구 실행 |
| STEP 5 | Data Integration | - 이 단계에서는 앞 단계에서 수정 완료한 데이터를 ODS 내의 단일 통합 테이블에 적재하며, 다음의 단계를 거친다. - 선행 자료 또는 조건 : 데이터 클렌징 테이블, 데이터 충돌 판단 요건 - Step 1 : 통합 스토어드 프로시저 실행(예비 작업) - Step 2 : 통합 ETL 도구 실행 |
| STEP 6 | Data Export | - 앞 단계에서 통합된 데이터를 익스포트 규칙과 보안 규칙을 반영한 익스포트 ETL 기능을 수행해 익스포트 테이블을 생성한다. - 다양한 전용 DBMS 클라이언트 또는 데이터 마트, 데이터 웨어하우스에 적재한다. 해당 데이터는 OLAP 비정형 질의에 활용될 수 있다. |
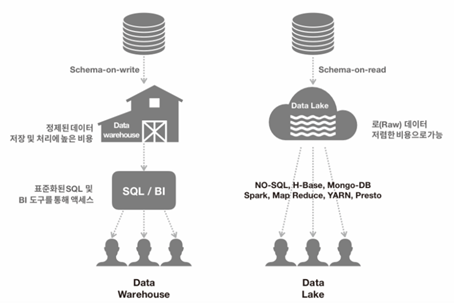
데이터 웨어하우스와 데이터 레이크 비교
| 속성 | 데이터 웨어하우스 | 데이터 레이크 |
|---|---|---|
| 스키마 | - Schema-on-write | - Schema-on-read |
| 액세스 방법 | - 표준화된 SQL 및 BI 도구를 통해 액세스 | - SQL과 유사한 시스템(NO.SQL, H-Base, Mongo-DB 등) - 개발자가 만든 프로그램(Spark, Map Reduce, YARN, Presto 등)을 통해 액세스 |
| 데이터 | - 정제된 데이터 | - 로 데이터 |
| 비용 | - 저장 및 처리에 높은 비용 | - 저렴한 비용으로 가능 |
| 특징 | - 빠른 응답시간 - 간편한 데이터 사용 - 간편한 데이터 사용 - 성숙한 거버넌스 체계 - 데이터 접근성이 제한적 - 정제되고 안전한 데이터 - 높은 동시성과 통합성 |
- 빠른 응답시간 - 간편한 데이터 사용 - 성숙한 거버넌스 체계 - 데이터 접근성이 매우 높음 - 단일 데이터 모델로부터 자유로움 - 저장 용량의 확장성이 좋음 - 도구의 확장성이 좋음 - 리얼타임 데이터 분석 가능 - 스트리밍 데이터 처리 - 단일 소스에서 정형&비정형 데이터 사용 가능 - 사용자가 응용프로그램 및 쿼리를 커스터마이징해서 사용 가능 - 민첩한 모델링 지원 - 빅데이터 분석 솔루션과 연동이 편리 |
3. 하둡 플랫폼에서의 데이터 저장과 처리
하둡 에코시스템
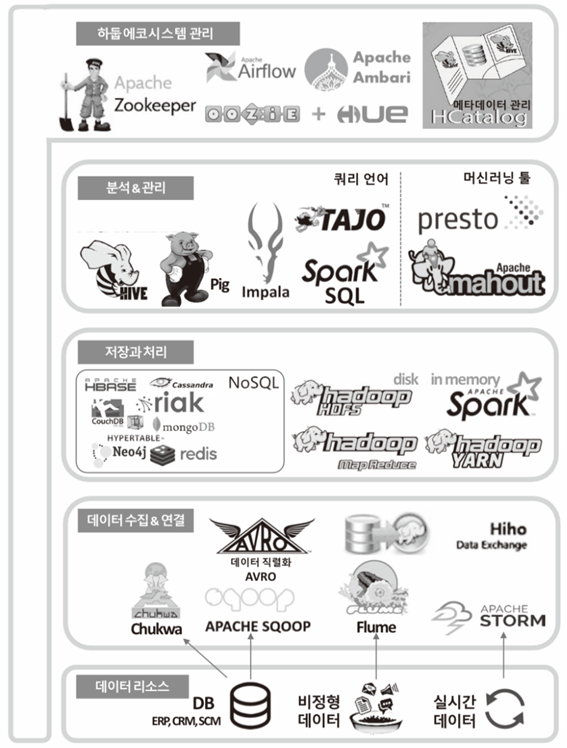
하둡 에코시스템 - 수집 및 연결 프레임워크
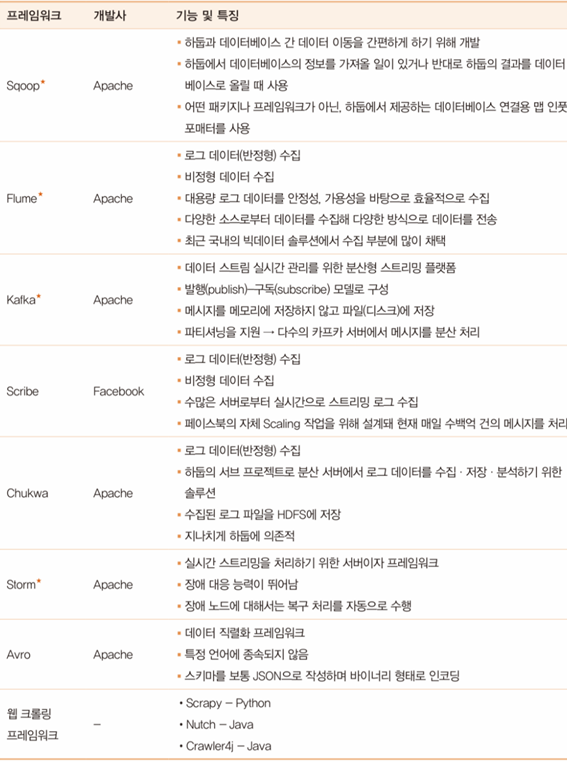
하둡 에코시스템 - 분석 및 관리 프레임워크
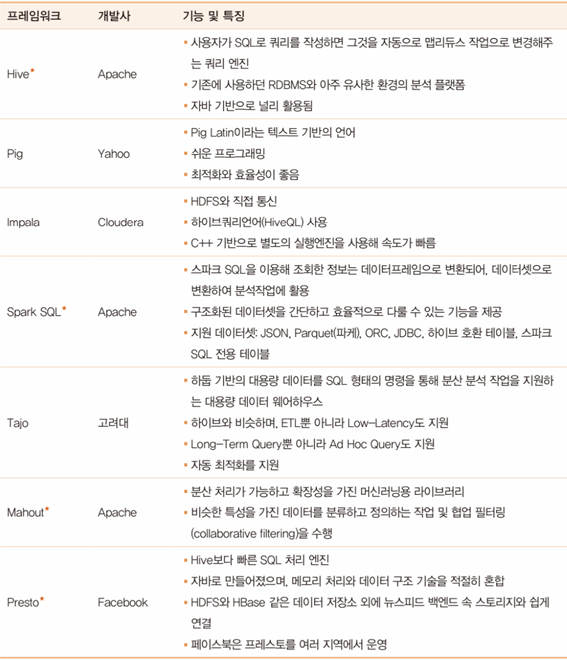
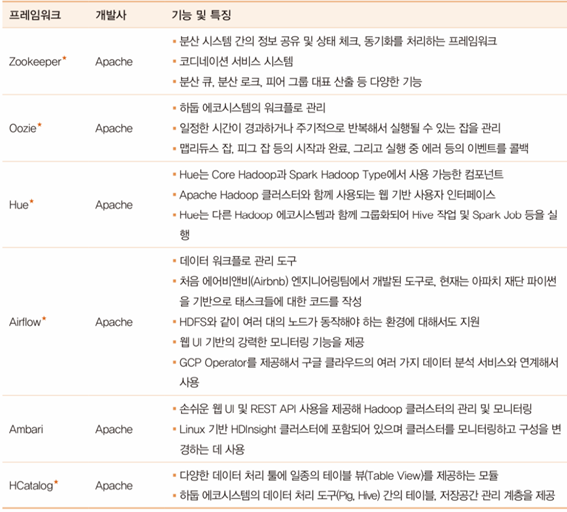
하둡 에코시스템 - 관리 프레임워크
출처
- 내용 출처
이지패스 2021 빅데이터분석기사 필기(수험서 앱 제공) / 위키북스 / 전용문, 정다혜, 임예은, 오경서 지음
[빅데이터 분석기사 필기 | 1. 빅데이터 분석 기획 (3) 데이터 수집 및 저장 계획]- 세우초밥